-
[ydata-profiling] 파이썬에서 ydata-profiling으로 간편하게 판다스 데이터 분석과 시각화Python/Pandas, Numpy 2023. 5. 11. 11:07반응형

ydata-profiling으로 간편한 데이터 분석과 시각화
파이썬(Python)을 사용할 때 데이터 시각화는 아주 중요하지만, 파이썬과 친하지 않은 사람(비전공자라면 더욱 더)이라면 시각화를 하기까지 어려움이 너무 많습니다. 시각화 패키지는 어느정도의 함수, 클래스, 패키지 사용법을 외우고 있어야 사용이 가능하며, 똑같은 그래프라고 할지라도 입력 데이터를 바꾸려면 그게 또 일이거든요.
그래서, 저는 데이터 분석 초보자분들이 사용하기 너무 좋은 ydata-profiling 패키지를 한번 사용해 보시는걸 권장드리고 있습니다. 초보자들은 고급 대시보드 패키지에서나 사용할 수 있는 전반적인 데이터 개요를 손쉽게 살펴볼 수 있어서 만족스럽고, 코딩을 잘 하는 분들이라도 코드 몇 줄 쓰지 않고 데이터를 대충 훑어볼 수 있기 때문입니다. 패키지 설치는
$ pip install -U ydata-profiling명령어를 입력하며, 공식 홈페이지에서 더욱 자세한 정보를 찾아볼 수 있습니다.ydata-profiling은 이전에 pandas_profiling이라는 이름으로 불리던 패키지입니다. 최근에 이름이 바뀌었는데, 당분간은 pandas_profiling의 설치와 사용을 지원하지만, 이후에는 ydata-profiling만 개발될 것으로 보입니다.
ydata-profiling 이용하기
ydata-profiling 패키지 사용법은 정말 간단합니다. 판다스(Pandas)와 ydata-profiling 패키지를 모두 불러온 뒤,
profile_report함수만 실행해 주면 되니까요. 이번 예제에서는 iris dataset을 사용해 보도록 하겠습니다. (데이터 출처)import pandas as pd import ydata_profilingdf = pd.read_csv('./Data/iris.csv') profile = df.profile_report() profile
※주피터 노트북의 HTML 렌더링 내용을 그대로 보여드릴 수 없어서 결과물을 HTML파일로 첨부합니다
ydata-profiling을 사용하면, 함수 하나 실행했을 뿐인데 위와 같이 번지르르한 대시보드를 만나볼 수 있습니다. 판다스에서 기본적으로 지원하는
pd.describe함수보다 더욱 상세한 데이터 개요와 통계분석에서 고려해야 할 몇 가지 안내사항을 제공해 주고요, 데이터의 분포와 기초 통계 결과까지 한눈에 확인할 수 있습니다.df.describe()sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 1.000000 std 0.828066 0.435866 1.765298 0.762238 0.819232 min 4.300000 2.000000 1.000000 0.100000 0.000000 25% 5.100000 2.800000 1.600000 0.300000 0.000000 50% 5.800000 3.000000 4.350000 1.300000 1.000000 75% 6.400000 3.300000 5.100000 1.800000 2.000000 max 7.900000 4.400000 6.900000 2.500000 2.000000 참고로,
pd.describe함수는 이렇습니다.산점도(scatterplot)과 상관관계 분석(correlation analysis) 등이 자동으로 진행되기 때문에, 이정도라면 데이터의 특성을 알아보는 용도로는 차고 넘치는 수준이라고 생각됩니다. 데이터 전처리를 잘 해둔 상태라면 이 결과를 그대로 보고서에 써도 될 듯한 느낌이네요.
만약 ydata-profiling 정보를 문서가 아니라 위젯 형태로 보고 싶다면,
to_widgets함수를 이용해 형태를 변경할 수 있습니다.profile.to_widgets()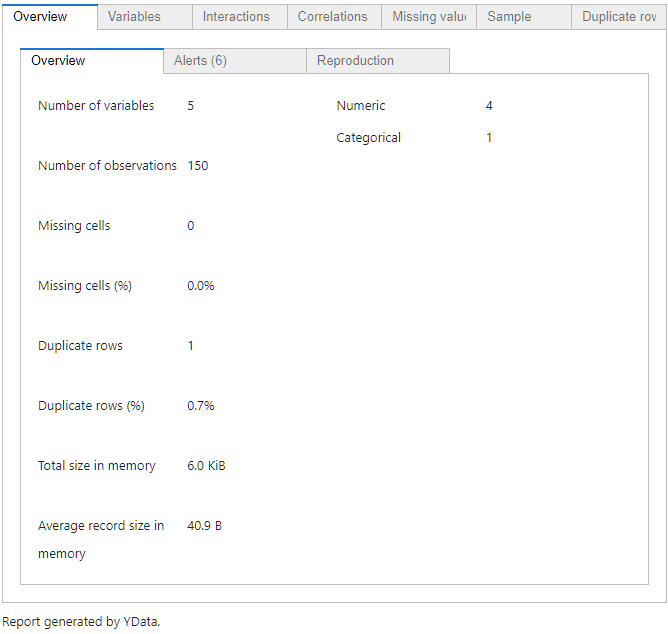
ydata-profiling 결과 파일로 내보내기
ydata-profiling으로 시각화한 결과는 주피터 노트북(jupyter notebook)에서 손쉽게 확인할 수 있지만, 별도 배포가 필요한 경우에는 HTML 파일로 내보내는게 편할 수 있습니다. 만약 데이터를 HTML 파일로 내보내기할 경우,
to_file함수를 이용하면 됩니다.profile.to_file('./report.html')Export report to file: 0%| | 0/1 [00:00<?, ?it/s]※출력 결과는 위에 첨부해드린 report.html 파일을 참조해 주시기 바랍니다.
반응형'Python > Pandas, Numpy' 카테고리의 다른 글
[Pandas] 판다스 merge 함수로 파이썬 데이터프레임 병합하는 방법 (2) 2023.05.17 [Pandas] 파이썬 Pandas로 엑셀 파일 읽기와 쓰기 (0) 2023.05.04 [Pandas] 판다스 마스킹과 쿼리 함수 이용하기 (1) 2023.04.25