-
웹 검색 기능이 탑재된 챗봇 구현해보기 (chatGPT API)Python/자연어처리 2025. 7. 30. 16:54반응형

웹 검색 기능이 탑재된 챗봇 구현해보기 (chatGPT API)
나만의 챗봇을 만들 때 흔히 이용하는 기술 중 하나가 RAG입니다. RAG는 단순히 외부 문서를 참조하는것 이외에도, 웹사이트 정보를 크롤링한 다음 참조하는 방식으로 웹 검색과 유사한 기능을 구현할 수 있어요. 이번에는 이런 설계를 활용해서 chatGPT API와 🦜️🔗랭체인(Langchain)을 이용해서 웹 검색 기능이 탑재된 챗봇을 구현해 보도록 하겠습니다. 이 프로그램을 만들기 전에는 랭체인을 설치하고 OpenAI API 키 발급을 해 놓는 정도의 준비만 해 두시면 됩니다.
웹 검색 기능 설계하기
웹 검색 기능을 구현하기 위해서는 크게 두 가지 접근 방법을 고민할 수 있습니다. 제작 목적 및 편의성, 예산에 따라 알맞은 방법을 선택해 보세요.
- 자연어로 작성한 검색어를 입력받으면, 검색 API를 활용해 검색한 뒤 그 결과를 요약해서 전달해주는 검색 챗봇
- 검색할 웹사이트를 미리 정하거나 입력받으면, 해당 페이지 안에 있는 정보를 검색 및 요약하는 챗봇
이번에는 둘 중에 후자의 방법을 이용한 챗봇을 구현해 보려고 합니다. 검색 대상이 되는 웹페이지를 검색 증강 생성(RAG) 방식을 활용해 입력시키고, 해당 내용을 참조해 답변하도록 설계합니다.
웹페이지 정보 저장하기
웹페이지의 정보는 텍스트만 남기고 나머지는 삭제하는 방법으로 추출합니다. 이렇게 하면 웹 구조 및 멀티미디어는 누락될 수 있지만, 텍스트 기반의 정보는 효율적으로 스크래핑할 수 있기 때문에 대부분의 웹사이트를 대응할 수 있도록 해 줍니다. 웹페이지 로드 및 저장은 랭체인의
WebBaseLoader클래스를 활용합니다.from langchain.document_loaders import WebBaseLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import FAISS from langchain.chains import RetrievalQA from langchain_openai import ChatOpenAI, OpenAIEmbeddings import os # API 키 입력 os.environ["OPENAI_API_KEY"] = "API_KEY" embeddings = OpenAIEmbeddings() def load_webpage(url): loader = WebBaseLoader(url) documents = loader.load() return documentsRAG 구현하기
다음으로는, 저장된 웹페이지 정보를 분할한 다음 벡터화 과정을 거쳐 벡터 저장소로 변환하는 과정입니다. 이렇게 하면 벡터 저장소를 LLM이 참조하도록 입력할 수 있지요.
def build_vectorstore(documents): global embeddings splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=100 ) docs = splitter.split_documents(documents) vectorstore = FAISS.from_documents(docs, embeddings) return vectorstoreLLM 질의응답 기능 구현
마지막으로는 LLM 모델을 정의하고 질의응답을 할 수 있도록 QA 체인을 구현하는 과정입니다. 이 때, 필요에 따라 모델 종류 및 temperature 설정을 함으로써 LLM 모델의 성능 및 응답 특성을 조절할 수 있답니다.
def create_qa_chain(vectorstore): llm = ChatOpenAI(temperature=0.3) return RetrievalQA.from_chain_type( llm=llm, retriever=vectorstore.as_retriever(), return_source_documents=False ) def run_query_over_url(url, question): print(f" - 웹페이지를 검색하는 중입니다: {url}") documents = load_webpage(url) vectorstore = build_vectorstore(documents) qa_chain = create_qa_chain(vectorstore) return qa_chain.invoke(question)['result']url = "https://www.aladin.co.kr/shop/common/wbest.aspx?BranchType=1&start=we" question = "돌비공포라디오 책 정보" result = run_query_over_url(url, question) print("\n 답변 💬:") print(result)- 웹페이지를 검색하는 중입니다: https://www.aladin.co.kr/shop/common/wbest.aspx?BranchType=1&start=we 답변 💬: 돌비공포라디오 책은 국내도서 중 하나로, 무서운 실화 레전드 괴담집을 다루고 있습니다. 책의 지은이는 돌비이며, 판매처는 arte(아르테)입니다. 책의 정가는 19,800원이지만 10% 할인된 가격으로 17,820원에 판매되고 있습니다. 또한, 이 책을 구매하면 990원의 마일리지를 적립할 수 있습니다. 발매 예정일은 2025년 7월이며, 세일즈포인트는 38,480입니다.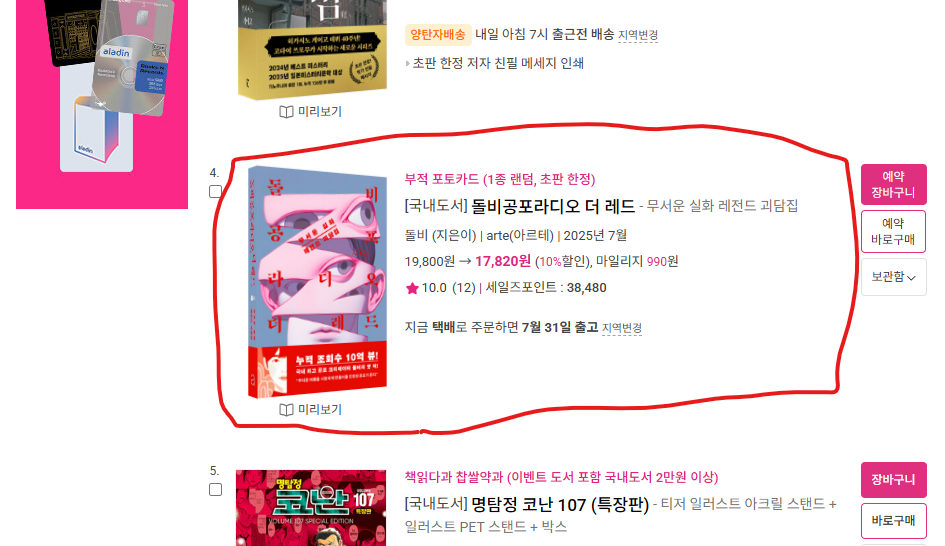
이제 run_query_over_url 함수에 웹페이지 URL과 자연어 질문을 함께 입력하면 편리하게 웹 검색 기반의 챗GPT 검색 챗봇을 구현할 수 있습니다. 위 코드는 알라딘 베스트셀러 페이지에 접속한 다음, 특정 책 정보를 알아보도록 명령하는 코드를 작성했습니다. 이외에도 다른 웹사이트 주소를 입력해서 원하는 정보를 검색하도록 할 수 있지요.
반응형'Python > 자연어처리' 카테고리의 다른 글
프롬프트 인젝션 공격에 대해 알아보기 (3) 2025.07.29 chatGPT가 거짓말 못하게 하는 방법, RAG에 대해 알아보기 (1) 2025.07.24 [Transformers] 🤗 트랜스포머로 파이썬 텍스트 분석 모델 이용하기 (1) 2024.10.07