-
KIND 공시 데이터로 교육서비스업 상장법인 정보 알아보기: 파이썬 크롤링 정리Python/크롤링 2026. 1. 20. 16:15반응형

요약
KIND 데이터를 활용하면 서울특별시에 소재한 교육 서비스업 상장법인 목록과 주요 정보를 정형화된 방식으로 수집할 수 있습니다. 이 글에서는 Selenium(셀레니움)과 BeautifulSoup(뷰티풀수프), pandas(판다스)를 이용해서 해당 데이터를 크롤링하는 과정을 차례대로 정리합니다.
상장법인 목록을 조회하려면
재무 분석이나 산업 분석을 하다 보면 특정 조건을 만족하는 상장법인 목록이 필요한 순간이 찾아옵니다. 예를 들어, 저는 최근에 서울특별시 소재 교육 서비스업 상장사만 따로 정리할 일이 있었습니다. 한국거래소 KIND 사이트에는 필요한 정보가 모두 있지만, 엑셀 파일 일괄 다운로드를 하면 회사명, 시장구분, 종목코드, 업종, 주요제품, 상장일, 결산월, 대표자명, 홈페이지, 지역 데이터만 확인할 수 있어서 활용도가 조금 떨어집니다.
회사명 시장구분 종목코드 업종 주요제품 상장일 결산월 대표자명 홈페이지 지역 데이원컴퍼니 코스닥 373160 기타 교육기관 성인대상 교육서비스 2025-01-24 12월 이강민 http://day1company.co.kr/ 서울특별시 아이비김영 코스닥 339950 일반 교습 학원 오프라인 학원, 온라인강의 2019-12-24 12월 김석철 http://www.kimyoung.co.kr 서울특별시 메가엠디 코스닥 133750 일반 교습 학원 의학, 치의학, 법학 전문대학원, 약학대학 입학시험 대비 강의 2015-12-18 12월 윤용국 http:// http://www.megamd.co.kr 서울특별시 [표 1] KIND에서 제공하는 엑셀 일괄 다운로드 데이터 예시
만약 다른 데이터를 원한다면, 사람이 하나씩 클릭해서 확인하도록 설계돼 있고 별도 API가 제공되고 있지 않다는게 문제입니다. 기업 수가 몇 개 안 된다면 수작업도 가능하겠지만, 페이지 이동과 새 창 열기를 반복하다 보면 생각보다 시간이 많이 소모됩니다.
이런 상황에서 자동화가 가능하다면 시간을 많이 절약할 수 있겠지요. 실제 사람이 사이트를 사용하는 흐름을 그대로 따라가면서 필요한 정보만 구조화해 가져오는 방식으로 KIND 데이터 크롤링에 도전해 봅시다.
KIND 사이트 구조와 접근 방식
KIND는 정적 페이지가 아니라, 조건 검색과 페이지 이동이 자바스크립트 기반으로 동작하는 동적 웹사이트입니다. 업종과 지역을 선택한 뒤 검색 버튼을 누르면 결과가 갱신되고, 각 회사명을 클릭하면 새 창으로 상세 정보가 열린답니다. 이 구조 때문에 requests만으로는 접근이 어렵고, 실제 브라우저 동작을 흉내 낼 수 있는 Selenium을 사용하는 쪽이 훨씬 수월합니다.

[이미지 1] KIND 상장법인 조회 페이지 이번 목표는 업종을 교육 서비스업, 지역을 서울특별시로 제한하고, 검색 결과에 나타나는 모든 상장법인의 주요 정보를 하나의 데이터프레임으로 정리하는 것입니다. 이 과정에서 Selenium은 화면 조작을 담당하고, BeautifulSoup과 pandas는 HTML을 표 형태 데이터로 변환하는 역할을 맡습니다.
검색 조건 설정과 페이지 순회
먼저 selenium.webdriver가 KIND 상장법인 목록 페이지에 접속하도록 합니다. 상장법인 목록의 URL은 'https://kind.krx.co.kr/corpgeneral/corpList.do?method=loadInitPage' 이니 참고해 주세요. 이후에는 아래와 같이 동작하도록 설계해 보겠습니다.
- 업종 선택 박스에서 교육 서비스업을 선택
- 지역 선택 박스에서 서울특별시를 선택
- 검색 버튼을 누른다
- 페이지 하단의 페이지 정보를 읽어 마지막 페이지 번호를 구한다
여기까지 준비해 두면 검색 조건 및 페이지 순회를 위한 기본 정보를 알 수 있게 됩니다.
기업 상세 정보 수집
KIND에는 검색 결과 목록에서 각 회사명을 클릭하면 새 창이 열리고, 그 안에 기업의 기본 정보가 테이블 형태로 정리돼 있습니다. 이 페이지는 HTML 파싱할 수 있으니, 소스를 BeautifulSoup으로 파싱해 보겠습니다. table 태그를 pandas의 read_html로 읽어오면, 특별한 조작 없이도 HTML 테이블이 그대로 데이터프레임으로 변환되니 편리합니다.

[이미지 2] KIND 회사개요 페이지 다만 KIND의 기업 정보 테이블은 좌우로 나뉜 구조라, 그대로 사용하면 열 구조가 어색해집니다. 이를 해결하기 위해 테이블을 절반으로 나눈 뒤 좌측과 우측을 위아래로 병합하는(concat) 방식으로 정리했습니다. 이렇게 하면 항목명과 값이 한 줄씩 깔끔하게 대응됩니다. 이렇게 기업 하나를 처리할 때마다 창을 닫고 다시 메인 창으로 돌아오는 흐름을 유지하면, 브라우저 잘못 동작하지 않고 크롤링을 할 수 있게 됩니다.
데이터 누적과 CSV 저장
각 기업에서 추출한 데이터는 하나의 결과 데이터프레임에 순차적으로 추가합니다. 중간중간 CSV 파일로 저장해 두면, 크롤링 도중 예기치 않은 오류가 발생하더라도 이미 수집한 데이터는 유지할 수 있으니 중간 저장을 생활화합시다.
한글명 표준코드 설립일 대표이사 자본금(한국원) 결산월 업종 주요제품 주소 홈페이지 영문명 종목코드 시장구분 상장일 종업원수 전화번호 지정자문인 데이원컴퍼니 KR7373160001 2017-04-17 이강민 6.9E+09 12 월 기타 교육기관 성인대상 교육서비스 서울특별시 강남구 테헤란로 231 West동 6층,7층(역삼동,센터필드) day1company.co.kr/ Day1 Company 373160 코스닥 상장 2025-01-24 372 명 02-501-9396 NaN 아이비김영 KR7339950008 2019-10-11 김석철 4.5E+09 12 월 일반 교습 학원 오프라인 학원, 온라인강의 서울특별시 서초구 강남대로 279 4,5층(서초동, 백향빌딩) www.kimyoung.co.kr IBKIMYOUNG 339950 코스닥 상장 2019-12-24 195 명 02-3456-8013 NaN 메가엠디 KR7133750000 2004-01-19 윤용국 1.2E+10 12 월 일반 교습 학원 의학, 치의학, 법학 전문대학원, 약학대학 입학시험 대비 강의 서울특별시 서초구 반포대로 81 2층(서초동, 영림빌딩) http://www.megamd.co.kr MegaMD 133750 코스닥 상장 2015-12-18 300 명 02-6918-3505 NaN [표 2] KIND 회사 개요 데이터 예시
최종 생성되는 CSV 파일에는 서울특별시에 위치한 교육 서비스업 상장법인의 주요 정보가 행 단위로 정리되어 있기 때문에, 이후 이 데이터를 기반으로 추가 분석이나 시각화를 진행하기에 적합한 형태로 관리할 수 있습니다.
함께 알아두면 좋은 점
KIND 사이트뿐만 아니라, 웹 사이트를 크롤링할 때는 인터넷 및 서버 상태에 따라 간헐적으로 로딩 속도가 느려질 수 있습니다. 그래서 페이지 전환이나 새 창 로딩 뒤에는 짧은 대기 시간을 주는 편이 안전합니다. 또한, 버튼의 XPath는 웹 사이트 개편 및 화면 구성에 따라 달라질 수 있으므로, 실제 실행 환경에서 한 번쯤 점검하는 것이 좋습니다. XPath는 개발자 도구를 이용해서 쉽게 확인할 수 있습니다.
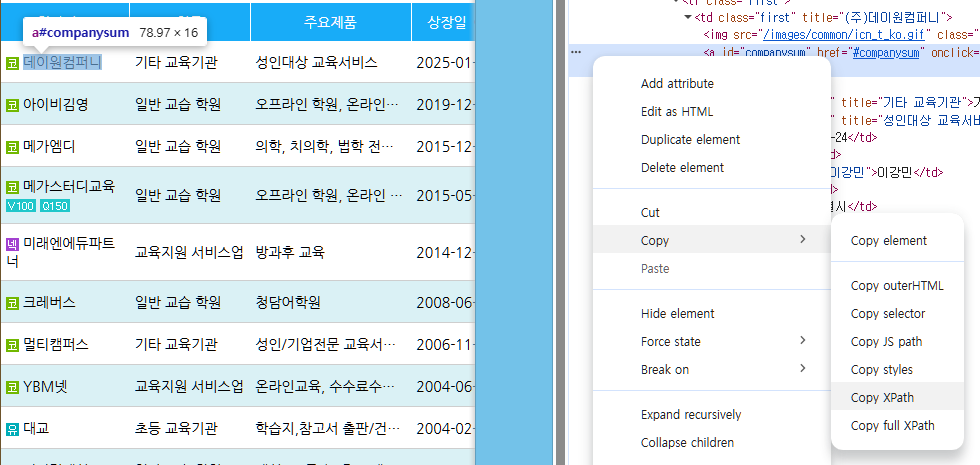
[이미지 3] XPath 확인하기 KIND 데이터를 활용한 상장법인 수집은 실제 분석 작업에서 손쉽게 활용할 수 있는 데이터이기 때문에, 비슷한 방식으로 업종이나 지역 조건을 바꿔서 연습해 보시기 바랍니다. 다른 산업군 데이터도 같은 구조로 정리할 수 있으니 업종과 관계 없이 유용한 스킬이기 때문입니다.
예제 코드
위 교육자료를 읽어본 뒤, 아래 코드를 실행해 보며 파이썬 코드가 어떻게 동작하는지 살펴보시기 바랍니다.
# import package from selenium import webdriver from selenium.webdriver.common.by import By from bs4 import BeautifulSoup import re import time import pandas as pd from io import StringIO driver = webdriver.Chrome() driver.get('https://kind.krx.co.kr/corpgeneral/corpList.do?method=loadInitPage') # 업종: 정보통신업, 지역: 서울특별시 검색 driver.find_element(By.XPATH,'//*[@id="industry"]/option[text()="교육 서비스업"]').click() driver.find_element(By.XPATH,'//*[@id="location"]/option[text()="서울특별시"]').click() driver.find_element(By.XPATH,'//*[@id="searchForm"]/section/div/div[3]/a[1]').click() time.sleep(1) # 마지막 페이지 구하기 element = driver.find_element(By.XPATH, '//*[@id="main-contents"]/section[2]/div[2]') last_page = int(re.findall('/\d+', element.text)[0][1:]) result = pd.DataFrame() company_list = driver.find_elements(By.XPATH, f'//*[@id="companysum"]') # 업체 목록 구하기 for page in range(1, last_page+1): for company in company_list: company.click() time.sleep(1) driver.switch_to.window(driver.window_handles[-1]) # 마지막 창으로 전환 soup = BeautifulSoup(driver.page_source, 'html.parser') table_tag = str(soup.find_all('table')[0]) df = pd.read_html(StringIO(table_tag))[0] half = df.shape[1] // 2 left = df.iloc[:, :half] right = df.iloc[:, half:] right.columns = left.columns df2 = pd.concat([left, right], ignore_index=True) df2 = df2[df2[0] != df2[1]] df2.index = df2[0] df2 = pd.DataFrame([df2[1]]) if len(driver.window_handles) != 1: driver.close() driver.switch_to.window(driver.window_handles[0]) # 첫 번째 창으로 전환 result = pd.concat([result, df2], ignore_index=True) result.to_csv('./result.csv', index=False) try: driver.find_element(By.XPATH, f'//*[@id="main-contents"]/section[2]/div[1]/a[7]').click() # 다음 버튼 except: continue반응형'Python > 크롤링' 카테고리의 다른 글
[Selenium] 진학어플라이 정시 경쟁률 정보 크롤링하기 (0) 2025.03.26 [BeautifunSoup] 파이썬으로 네이버페이 증권 종목토론실 데이터 크롤링하기 - 2 (2) 2025.02.25 [BeautifunSoup] 파이썬으로 네이버페이 증권 종목토론실 데이터 크롤링하기 (4) 2025.02.24