-
[scikit-learn] 기계학습 모델 평가용 k-Fold Cross Validation 알아보기Python/기계학습 2024. 3. 14. 10:24반응형
기계학습 모델 평가를 위한 k-Fold Cross Validation 알아보기
기계학습 모델을 만든 뒤, 학습만 끝냈다고 해서 모든 문제가 해결되는게 아닙니다. 얼마나 잘 돌아가는 모델을 만들었는지 평가(Validation)하는 과정이 필요한데요, 이번에는 파이썬(Python)의 기계학습 패키지인 사이킷런(scikit-learn)에서 제공하는 교차 검증(Cross Validation) 기능을 알아보도록 하겠습니다.
교차 검증
교차 검증이란, 데이터의 다양한 부분집합을 사용해서 모델을 테스트하는 검증 기술입니다. 기계학습(지도학습에 한해 설명합니다)은 항상 학습 데이터(training set)의 특징에 지나치게 의존도하게 되는 과적합(overfitting) 문제가 발생할 위험이 있는데, 이를 방지하기 위해 테스트 데이터(test set)를 이용해서 검증하는 과정을 포함해야 합니다. 이 때, 오히려 테스트 데이터에 과적합될 위험을 해결하기 위해 교차 검증을 하는 것을 권장합니다. 사이킷런에서는
sklearn.model_selection모듈에서 k-Fold Cross Validation 등의 교차 검증을 지원하고 있습니다.k-Fold Cross Validation
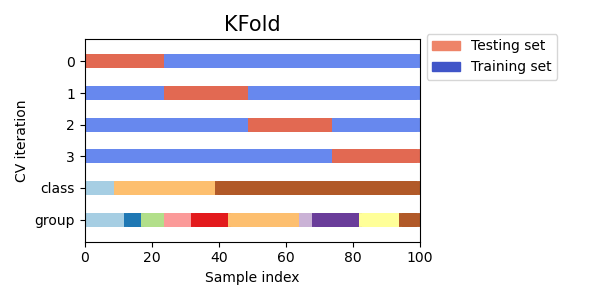
[그림 1] k-Fold Cross Validation의 도식화 (출처) K겹 교차 검증(k-Fold Cross Validation)은 확보된 데이터를 k개로 나눈 뒤, (k-1)개 집합을 학습 데이터로, 나머지 하나의 집합을 테스트 데이터로 활용하는 방법입니다. 이 때, k등분으로 데이터를 나눌 수 있는 경우의 수는 k가지이므로, 검증 과정은 총 조합에 따라 총 k번 반복되게 됩니다. 이렇게 된다면 단순히 테스트 데이터를 설정했을 때에 비해서 같은 데이터 양으로도 더욱 정확한 교차 검증이 가능하다는 장점이 있지요.
사이킷런에서는sklearn.model_selection.KFold로 구현할 수 있으니, 아래 코드를 참조해 의사결정나무 분류기(Decision Tree Classifier) 모델을 k-Fold Cross Validation으로 검증해 보도록 하겠습니다.# import package from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score from sklearn.model_selection import KFold import numpy as np from sklearn.datasets import load_iris # input data, ML model iris = load_iris() X = iris.data y = iris.target dt_clf = DecisionTreeClassifier(random_state=12345) # 5-fold CV kfold = KFold(n_splits=5, shuffle=False) cv_index = kfold.split(X) cv_accuracy = [] ind = 1 for train_index, test_index in cv_index: X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] dt_clf.fit(X_train , y_train) accuracy = dt_clf.score(X_test, y_test) print(f'{ind}번째 Cross Validation 정확도: {accuracy:.2%}') cv_accuracy.append(accuracy) ind += 1 print(f'''------------------------------------------- Cross Validation 정확도 평균: {np.mean(cv_accuracy):.2%}''')1번째 Cross Validation 정확도: 100.00% 2번째 Cross Validation 정확도: 100.00% 3번째 Cross Validation 정확도: 83.33% 4번째 Cross Validation 정확도: 93.33% 5번째 Cross Validation 정확도: 73.33% ------------------------------------------- Cross Validation 정확도 평균: 90.00%Stratified k-Fold Cross Validation
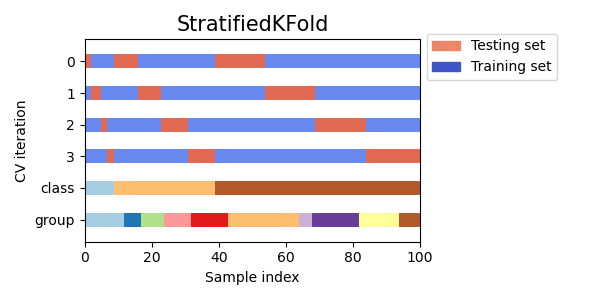
[그림 2] Stratified k-Fold Cross Validation의 도식화 (출처) 층화 K겹 교차 검증(Stratified k-Fold Cross Validation)은 확보된 데이터를 k개로 나눈다는 점은 일반적인 k-Fold Cross Validation과 동일합니다. 하지만, 각 데이터 집합에서는 클래스의 비율이 모집합과 같이 유지된다는 차이점을 보이는데요, 이 때문에 Stratified k-Fold Cross Validation는 특정 클래스의 쏠림으로 인해 검증 결과가 편향되는 문제를 근본적으로 해결할 수 있다는 장점ㅇ 있습니다.
사이킷런에서는sklearn.model_selection.StratifiedKFold를 이용해서 Stratified k-Fold Cross Validation를 구현할 수 있습니다. 아래 코드를 참조해서, 이전에 만든 Decision Tree Classifier 모델의 k-Fold Cross Validation 검증 결과와 Stratified k-Fold Cross Validation 검증 결과를 서로 비교해 보도록 하겠습니다.# import package import pandas as pd from sklearn.model_selection import StratifiedKFold # imput data iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) iris_df['species'] = iris.target # 3-fold CV kfold = KFold(n_splits=3, shuffle=False) ind = 1 for train_index, test_index in kfold.split(X): train_label = iris_df.loc[train_index, 'species'] test_label = iris_df.loc[test_index, 'species'] print( f'''\033[1m[{ind}번째 3-Fold Cross Validation]\033[0m * training set 데이터 분포 {train_label.value_counts()} * test set 데이터 분포 {test_label.value_counts()}''' ) ind += 1 print('-'*50) # Stratified 3-fold CV skfold = StratifiedKFold(n_splits=3) ind = 1 for train_index, test_index in skfold.split(X, y): train_label = iris_df.loc[train_index, 'species'] test_label = iris_df.loc[test_index, 'species'] print( f'''\033[1m[{ind}번째 Stratified 3-Fold Cross Validation]\033[0m * training set 데이터 분포 {train_label.value_counts()} * test set 데이터 분포 {test_label.value_counts()}''' ) ind += 1[1번째 3-Fold Cross Validation] * training set 데이터 분포 1 50 2 50 Name: species, dtype: int64 * test set 데이터 분포 0 50 Name: species, dtype: int64 [2번째 3-Fold Cross Validation] * training set 데이터 분포 0 50 2 50 Name: species, dtype: int64 * test set 데이터 분포 1 50 Name: species, dtype: int64 [3번째 3-Fold Cross Validation] * training set 데이터 분포 0 50 1 50 Name: species, dtype: int64 * test set 데이터 분포 2 50 Name: species, dtype: int64 -------------------------------------------------- [1번째 Stratified 3-Fold Cross Validation] * training set 데이터 분포 2 34 0 33 1 33 Name: species, dtype: int64 * test set 데이터 분포 0 17 1 17 2 16 Name: species, dtype: int64 [2번째 Stratified 3-Fold Cross Validation] * training set 데이터 분포 1 34 0 33 2 33 Name: species, dtype: int64 * test set 데이터 분포 0 17 2 17 1 16 Name: species, dtype: int64 [3번째 Stratified 3-Fold Cross Validation] * training set 데이터 분포 0 34 1 33 2 33 Name: species, dtype: int64 * test set 데이터 분포 1 17 2 17 0 16 Name: species, dtype: int64위와 같이, 일반적인 k-Fold CV에 비해 Startified k-Fold CV는 각 클래스 정보가 일정한 비율로 들어가 있는 것을 확인할 수 있습니다. 위 데이터의 경우 input data를 섞지 않았기 때문에, 데이터의 순서를 섞어서 학습시킨다면 위와 같은 차이는 보이지 않을 수 있습니다. 하지만, 무작위 추출의 특성상 데이터의 쏠림이 일어날 수 있으므로 특별한 문제가 없는 경우에는 Startified k-Fold CV를 이용해서 모델 검증을 하는 것을 권장드립니다.
dt_clf = DecisionTreeClassifier(random_state=12345) skfold = StratifiedKFold(n_splits=3) ind=1 cv_accuracy=[] # Stratified 5-fold CV skfold = StratifiedKFold(n_splits=5, shuffle=False) cv_index = skfold.split(X, y) cv_accuracy = [] ind = 1 for train_index, test_index in cv_index: X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] dt_clf.fit(X_train , y_train) accuracy = dt_clf.score(X_test, y_test) print(f'{ind}번째 Cross Validation 정확도: {accuracy:.2%}') cv_accuracy.append(accuracy) ind += 1 print(f'''------------------------------------------- Cross Validation 정확도 평균: {np.mean(cv_accuracy):.2%}''')1번째 Cross Validation 정확도: 96.67% 2번째 Cross Validation 정확도: 96.67% 3번째 Cross Validation 정확도: 90.00% 4번째 Cross Validation 정확도: 96.67% 5번째 Cross Validation 정확도: 100.00% ------------------------------------------- Cross Validation 정확도 평균: 96.00%그리고, Startified k-Fold CV를 이용해 Decision Tree 모델을 검증한 결과는 위와 같이 나타납니다. 앞서 진행했던 k-Fold CV에 비해 정확도가 일정하게 나타나는 것을 확인할 수 있지요.
반응형'Python > 기계학습' 카테고리의 다른 글
[scikit-learn] 머신러닝 최적화를 위한 GridSearch, RandomSearch CV 알아보기 (0) 2024.03.14 [scikit-learn] 사이킷런 레이블인코더, 원-핫 인코더로 기계학습 데이터 전처리하기 (0) 2024.03.13 [scikit-learn] 사이킷런 라벨 인코딩을 이용한 전처리 (python LabelEncoder) (1) 2023.10.10